
Why We Built Our Own AI for SAP PII Detection — And Beat a Foundation Model
- Ben Ramhofer

- Jun 3
- 8 min read
Updated: Jun 4

A benchmark comparison: Maya Data Privacy's PIIDetect and PIIClassify vs. SAP RPT-1 OSS on 386,956 rows of SAP metadata.
The Problem: Finding Personal Data in SAP Is Harder Than It Looks
SAP systems are the backbone of enterprise operations. They store everything from employee records and customer master data to financial transactions and healthcare information. Across thousands of tables and hundreds of thousands of fields, personal data is everywhere, but it is not labeled, not consistent, and not easy to find.
For organizations navigating GDPR, particularly Art. 25 (Privacy by Design) and Art. 30 (Records of Processing Activities), accurately identifying every field that contains personal data is not optional. It is the basis of compliant data handling, whether for test environments, analytics, AI training, or system migrations.
The challenge is that SAP metadata is complex. Field names like KUNNR, PERNR, or BNAME carry meaning only if you understand SAP's domain-specific naming conventions. Traditional rule-based approaches miss too much, and manual classification across thousands of tables is neither scalable nor reliable.
This is why we turned to AI.
Starting Point: Evaluating SAP RPT-1 OSS
When we began building AI-driven PII discovery at Maya Data Privacy, the natural first step was to evaluate a state-of-the-art tabular foundation model. SAP RPT-1 is pretrained on 1.34 TB of structured data across 3.1 million tables and is built for general-purpose tabular prediction. We benchmarked the open-source release, SAP RPT-1 OSS.
On paper it seemed like a strong fit. SAP metadata is structured data; RPT-1 was trained on a vast amount of it. We ran it against our benchmark dataset. The results were promising in places, but not sufficient for the standards data privacy and governance demand.
The core issue: at its default threshold, SAP RPT-1 OSS catches only 66.4% of PII fields — roughly 1 in 3 personal data fields goes undetected out of the box. In privacy engineering, a missed PII field is not a minor inaccuracy. It is a field left unprotected in test copies, exposed in analytics pipelines, or visible to users who should never see it. It is a compliance gap.
We also observed significant GPU requirements and higher inference latency, making large-scale deployment more expensive and harder to operate, especially in secure enterprise environments where GPU infrastructure is not always available.
The Question That Changed Our Approach
This led us to a simple question: Can a purpose-built model outperform a general-purpose foundation model for this specific task?
The answer was yes.
Instead of treating PII detection as a generic tabular prediction problem, we reframed it as a semantic classification problem. SAP field names, table names, data element descriptions, and domain values carry rich semantic signals. The key was to build models that read those signals in context.
By combining SAP metadata understanding, sentence embeddings, and domain-specific engineered features, we developed two specialized, in-house models:
PIIDetect — binary PII detection (PII vs. Non-PII)
PIIClassify — multi-class PII classification (categorizing detected PII into specific types)
Both are part of AppSafe™, Maya's solution for anonymizing and pseudonymizing data inside SAP and enterprise applications.
Benchmark Results: PIIDetect (Binary PII Detection)
We ran both PIIDetect and SAP RPT-1 OSS on the same dataset of 386,956 rows of SAP metadata, under identical conditions.

Convention: "Remarks" shows the absolute difference in percentage points (pp); notable relative gaps are added in parentheses.
Metric | PIIDetect (Maya) | SAP RPT-1 OSS | Remarks |
PR-AUC | 0.9677 | 0.9575 | Maya +1.0 pp |
ROC-AUC | 0.9973 | 0.9966 | ≈ Tie (+0.1 pp) |
Accuracy | 0.9861 | 0.9727 | Maya +1.3 pp |
PII Recall (default threshold) | 0.912 | 0.664 | Maya +24.8 pp (+37% relative) |
PII Precision (default threshold) | 0.902 | 0.952 | SAP +5.0 pp |
PII F1 (default threshold) | 0.907 | 0.782 | Maya +12.5 pp (+16% relative) |
PII Recall (optimal threshold) | 0.912 | 0.900 | Maya +1.2 pp |
PII Precision (optimal threshold) | 0.902 | 0.858 | Maya +4.4 pp |
PII F1 (optimal threshold) | 0.907 | 0.878 | Maya +2.9 pp (+3% relative) |
We tested SAP RPT-1 OSS at both its default and an optimized threshold, to compare fairly. Even with threshold optimization, PIIDetect keeps the lead on recall, precision, and F1.
The most important number is PII Recall. In data privacy, recall is the metric that matters most: high precision tells you the model is right about what it flags, but low recall means it misses too much of what it should catch. At 66.4% recall, the foundation model leaves a third of all PII fields unprotected at its default threshold. PIIDetect catches 91.2%.
Benchmark Results: PIIClassify (Multi-Class PII Classification)
Once a field is identified as PII, the next step is classifying what type of personal data it holds — a name, an address, a date of birth, a bank account number. Accurate classification drives the right anonymization strategy.
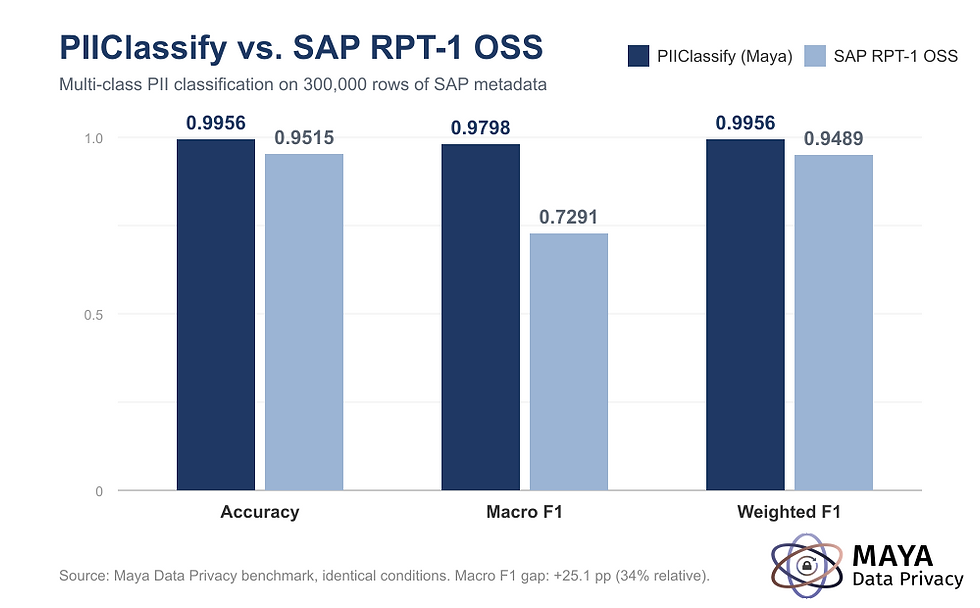
Convention: "Remarks" shows the absolute difference in percentage points (pp); notable relative gaps are added in parentheses.
Metric | PIIClassify (Maya) | SAP RPT-1 OSS | Remarks |
Accuracy | 0.9956 | 0.9515 | Maya +4.4 pp |
Macro F1 | 0.9798 | 0.7291 | Maya +25.1 pp (+34% relative) |
Weighted F1 | 0.9956 | 0.9489 | Maya +4.7 pp |
The Macro F1 gap of +25.1 pp is the standout. Macro F1 weights every PII category equally, so it shows PIIClassify performs consistently across rare and common PII types alike. The foundation model struggles with less frequent categories — which is exactly where classification errors create the biggest compliance risk.
Inference Speed and Deployment
Performance is only part of the equation. In enterprise environments, deployment constraints matter just as much.

These figures are the inference time per single row prediction, not for the entire dataset. At scale, that per-row gap compounds: across thousands of SAP tables and millions of fields, 0.14 seconds versus 4.75 seconds per prediction is the difference between a scan that finishes in minutes and one that runs for hours.
Metric | Maya's Models | SAP RPT-1 OSS |
Inference time (per row) | 0.14 s | 4.75 s |
Speed | 34× faster | Baseline |
Hardware | CPU only | GPU required |
34× faster inference, on CPU, with no GPU required. This is not a marginal improvement — it changes the deployment model entirely. Organizations running SAP in highly secure, air-gapped environments (common in healthcare, financial services, defense, and critical infrastructure) often cannot provision GPU infrastructure at all. A CPU-only model that runs faster is not just cheaper; it is the difference between deployable and not deployable.
Lower infrastructure requirements also mean lower operational costs, faster processing of large SAP landscapes, and simpler integration into existing CI/CD and DevOps pipelines.
Why Specialized Models Win in Enterprise AI
The broader lesson from this benchmark is not really Maya vs. SAP. It is that larger foundation models are not always the right answer.
Foundation models are powerful and generalize well across many tasks. But generalization has a cost: they optimize for breadth, not depth. For a specific, high-stakes problem like PII detection in SAP metadata, a model built around the problem domain can deliver:
Higher accuracy where it matters most — recall for PII fields
Better performance on edge cases — rare PII categories and SAP-specific naming
Lower operational cost — CPU vs. GPU, faster inference
Simpler deployment — no GPU provisioning, compatible with air-gapped environments
Faster time to value — less setup, quicker integration
This matches what we see across enterprise AI: the future is not just bigger models. It is the right model for the right problem.
What This Means for SAP Data Privacy
For organizations managing personal data in SAP, the implications are practical.
More complete PII coverage. Catching 91.2% of PII fields instead of 66.4% means fewer gaps in your data protection strategy — fewer unprotected fields in test copies, fewer compliance blind spots.
Faster processing at scale. When you need to scan thousands of SAP tables across multiple systems, 34× faster inference is the difference between a process that takes hours and one that takes minutes.
Deployable anywhere. CPU-only operation means PIIDetect and PIIClassify run in the same secure environments where your SAP systems already live, without additional GPU infrastructure.
Both models are integrated into AppSafe™, which uses AI-driven PII discovery as the first step in its anonymization pipeline. Once fields are identified and classified, AppSafe™ applies Privacy-Enhancing Technology (PET) based algorithms to create compliant production copies for testing, training, development, and AI use cases.
Conclusion
We built PIIDetect and PIIClassify because the problem demanded it. General-purpose foundation models are impressive, but for PII detection in SAP metadata a specialized approach delivers measurably better results: higher recall, higher accuracy, faster inference, and simpler deployment.
The benchmark data is clear. The right model for the right problem is not just a principle — it is a measurable advantage.
If your organization manages personal data in SAP and needs accurate, scalable PII discovery, we would be glad to show you how AppSafe™ works in practice.
FAQ
What is the best PII detection tool for SAP?
Maya Data Privacy's PIIDetect and PIIClassify are purpose-built AI models for finding personal data in SAP metadata. In a 300,000-row benchmark, PIIDetect caught 91.2% of PII fields versus 66.4% for the SAP RPT-1 OSS foundation model, while running 34× faster on CPU. Both are part of Maya's AppSafe™ anonymization solution.
PIIDetect vs. SAP RPT-1 OSS — which is better for PII detection in SAP?
On the same 300,000-row SAP metadata benchmark, Maya's PIIDetect outperformed the SAP RPT-1 OSS foundation model on PII recall (91.2% vs. 66.4%), F1, and accuracy, and ran 34× faster (0.14 s vs. 4.75 s) on CPU instead of GPU. SAP RPT-1 OSS had higher precision at its default threshold, but PIIDetect kept the overall lead even after threshold optimization.
How do you find personal data in SAP for GDPR compliance?
Finding personal data in SAP for GDPR means classifying every field that holds PII across thousands of tables, which rule-based methods miss. Maya Data Privacy's PIIDetect uses AI to detect PII fields and PIIClassify categorizes them by type, supporting GDPR Art. 25 (Privacy by Design) and Art. 30 (Records of Processing Activities). The output feeds AppSafe™, which anonymizes the data.
What is PIIDetect?
PIIDetect is Maya Data Privacy's binary AI model that identifies whether a field in SAP metadata contains personally identifiable information (PII). PIIDetect is purpose-built for SAP's domain-specific naming conventions and achieves 91.2% PII recall on a 300,000-row benchmark, outperforming the SAP RPT-1 OSS foundation model.
What is PIIClassify?
PIIClassify is Maya Data Privacy's multi-class AI model that categorizes detected SAP PII fields into types such as name, address, date of birth, or bank account number. PIIClassify achieves a Macro F1 of 0.9798, outperforming SAP RPT-1 OSS by 25.1 percentage points and driving the correct anonymization strategy in AppSafe™.
How were PIIDetect and PIIClassify benchmarked?
Maya Data Privacy benchmarked PIIDetect and PIIClassify against the SAP RPT-1 OSS foundation model on the same 300,000-row SAP metadata dataset, under identical conditions. The evaluation used accuracy, F1, precision, recall, PR-AUC, and ROC-AUC, testing both default and optimized thresholds for SAP RPT-1 OSS.
Why does PII recall matter more than precision in SAP data privacy?
In SAP PII detection, recall matters more than precision because a missed PII field (false negative) leaves personal data unprotected, creating a compliance risk under GDPR. A false positive only adds review work, with no compliance exposure. Maya's PIIDetect prioritizes recall, catching 91.2% of PII fields versus 66.4% for SAP RPT-1 OSS.
Can PIIDetect and PIIClassify run without GPU infrastructure?
Yes. PIIDetect and PIIClassify are designed for CPU-only deployment and require no GPU, making them suitable for air-gapped, highly secure SAP environments where GPU provisioning is not available or permitted. This is a key advantage over the SAP RPT-1 OSS foundation model, which requires a GPU.
How fast is PIIDetect compared to SAP RPT-1 OSS?
PIIDetect and PIIClassify run inference 34× faster than the SAP RPT-1 OSS foundation model — 0.14 seconds versus 4.75 seconds — while running on CPU instead of GPU. This makes scanning thousands of SAP tables a matter of minutes rather than hours.
What is SAP RPT-1 OSS?
SAP RPT-1 is a tabular foundation model from SAP, pretrained on 1.34 TB of structured data across 3.1 million tables for general-purpose tabular prediction. RPT-1 OSS is its open-source release, which Maya Data Privacy used as the baseline when benchmarking PIIDetect and PIIClassify for SAP PII detection.
How do PIIDetect and PIIClassify fit into AppSafe™?
PIIDetect and PIIClassify form the AI-driven PII discovery layer of Maya Data Privacy's AppSafe™. AppSafe™ uses their output to identify and classify personal data fields in SAP, then applies anonymization and pseudonymization algorithms to create compliant production copies for test, training, development, and AI use cases.
Is AI-driven PII detection relevant for S/4HANA migration?
Yes. S/4HANA migrations involve large-scale data movement and system testing that can expose personal data. Maya Data Privacy's PIIDetect provides accurate, automated PII detection that reduces this risk in migration test environments and supports GDPR Art. 25 (Privacy by Design) throughout the migration.
What regulations does Maya's SAP PII detection support?
Maya Data Privacy's AI-driven PII discovery supports alignment with GDPR (particularly Art. 25 on Privacy by Design and Art. 30 on Records of Processing Activities), the EU AI Act, and other data protection frameworks, helping organizations reduce the risk of non-compliance when handling personal data in SAP.



Comments