
80% of enterprise data sits unused: privacy is the reason, anonymization is the fix
- Ranbir
- Feb 7
- 4 min read

Enterprises are sitting on a goldmine of data. Customer transactions, operational records, HR data, supply chain logs, medical records, financial histories. Decades of accumulated business intelligence, captured in production systems across the organization.
Yet most of it never reaches an AI model. Gartner predicts that through 2026, organizations will abandon 60% of AI projects because they lack AI-ready data. The PEX Report 2025/26 confirms that data quality and availability are the greatest barriers to AI adoption. And Microsoft's 2026 Data Security Index found that the primary challenge isn't technology; it's the gap between data availability and data usability.
The root cause is rarely technical. It is regulatory. The most valuable enterprise data is also the most sensitive. And privacy regulations, rightly, prevent it from being used without proper safeguards.
The data paradox: your best data is your most restricted

Consider a mid-sized European bank. Its transaction data could power fraud detection models that save millions per year. Its customer interaction data could train AI assistants that reduce service costs by 30%. Its risk assessment data could feed credit scoring models that outperform rule-based systems.
But every one of these datasets contains personal data: names, account numbers, transaction details, behavioral patterns. Under GDPR, using this data for AI development without explicit consent or another lawful basis is a compliance violation. And under the EU AI Act, using uncontrolled personal data for high-risk AI applications will carry even steeper penalties.
So the data sits. Locked in production systems. Protected by access controls. Unavailable to the AI teams that could transform it into competitive advantage.
Why traditional workarounds fail
Organizations have tried several approaches to bridge this gap, with limited success:
Manual redaction: Some teams manually strip sensitive fields before sharing data with AI projects. This approach does not scale. A single SAP system can contain personal data across thousands of tables. Manual processes are slow, error-prone, and impossible to audit consistently.
Rule-based masking: Traditional masking tools replace sensitive values with random characters or fixed substitutions. While faster than manual work, these tools often break data relationships. A masked customer ID in one table no longer matches the same customer ID in another, destroying the referential integrity that makes enterprise data valuable for AI.
Synthetic data generation: Generating entirely artificial data avoids the privacy issue but introduces a different one: the synthetic data may not reflect the real complexity of production systems. Enterprise AI models trained on synthetic data often underperform when deployed against real-world inputs.
Data minimization to the extreme: Some organizations respond by restricting AI teams to aggregated or heavily summarized data. This eliminates privacy risk but also eliminates the granularity that makes machine learning effective.
The real solution: transform the data, not replace it
The enterprises getting this right have recognized a fundamental insight: the answer is not to avoid using real data. The answer is to make real data safe to use.
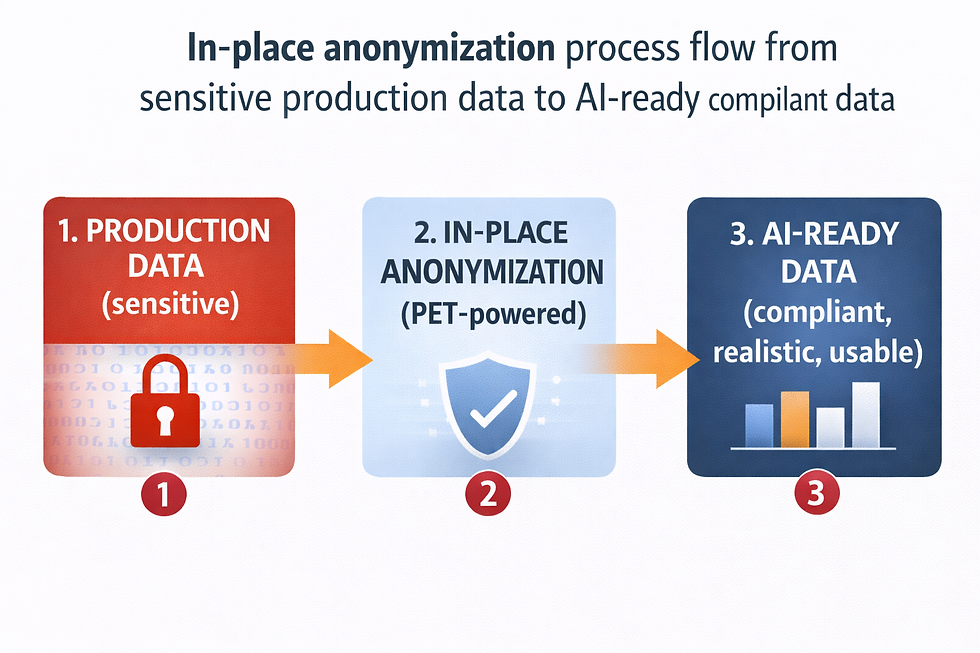
In-place anonymization achieves exactly this. Instead of copying data to external environments, generating artificial replacements, or manually stripping fields, it transforms personal identifiers directly within the organization's systems. The data retains its structure, distributions, and referential relationships. It just no longer identifies anyone.
What this looks like in practice:
An SAP S/4HANA environment with 5,000+ tables is anonymized consistently across all modules. Customer 'Anna Müller' becomes 'Petra Hoffmann' everywhere, in every table, in every connected system.
A hospital's patient record system generates anonymized datasets for AI model training, preserving diagnosis codes, treatment timelines, and outcome patterns without exposing any patient's identity.
A financial institution creates anonymized transaction histories for fraud detection model development, retaining the statistical patterns that make the models accurate.
The business impact of unlocking enterprise data
The difference between organizations that unlock their data and those that don't is increasingly measurable:
Faster AI development: teams working with production-quality anonymized data can build and validate models in weeks rather than months. No waiting for synthetic data to be generated and validated. No arguing with legal over data access requests.
Higher model accuracy: AI models trained on anonymized real data perform better than those trained on synthetic alternatives, because the data reflects genuine business complexity, including the edge cases and rare events that determine model performance in production.
Reduced regulatory risk: properly anonymized data falls outside GDPR scope entirely. AI teams can work freely with the data without triggering data protection impact assessments for every experiment.
Competitive differentiation: organizations that can safely leverage their full data estate for AI will out-innovate competitors who cannot. In industries like healthcare, finance, and manufacturing, the data advantage compounds over time.
From locked data to competitive advantage
The 80% of enterprise data sitting unused is not a technology problem. It is a privacy architecture problem. And it has a solution.
Privacy-enhancing technologies now make it possible to transform sensitive production data into AI-ready assets in days, not months. The technology exists. The regulatory frameworks support it. The only remaining question is organizational will.
Every week that valuable data remains locked in production systems is a week of AI innovation lost. The enterprises that move first will build models their competitors cannot match, because they will be training on data their competitors cannot access.
▸ Unlock your enterprise data for AI, safely and compliantly. Learn how Maya's Data for AI pipeline works → mayadataprivacy.eu/demo



One of the resources that gave me a similar impression was https://proshtuchnyiintelekt.com/, mainly because of its practical and easy-to-follow content
One of the resources that gave me a similar impression was https://101pryvitannia.com/, mainly because of its practical and easy-to-follow content
While looking for additional information, I recently came across https://krasatazdorovia.com/ and found several useful examples there
During my search for similar resources, I found https://novynypoltavy.com/, which also takes a straightforward and reader-friendly approach
During my search for similar resources, I found https://infowomenspace.com/, which also takes a straightforward and reader-friendly approach